In the evolving landscape of enterprise storage, the distinction between scale-up and scale-out storage architectures remains a focal point. As organizations face exponential data growth, understanding the nuances of these architectures is crucial for efficient storage management and expansion.
Storage capacity is the primary benchmark for evaluating storage devices, closely followed by the ease of capacity expansion. The urgency of scaling is a critical concern for storage administrators, often requiring a choice between adding hardware to an existing system or architecting a more complex solution such as a new data center. The former, known as scale-up, and the latter, scale-out, are differentiated by their inherent architectural designs.
The Traditional Scale-Up Model
Scale-up storage has been the traditional approach. It typically involves a central pair of controllers overseeing multiple shelves of drives. Expansion is linear and limited; when space runs out, additional shelves of drives are integrated. The limitation of this model lies in the finite scalability of the storage controllers themselves.
As storage demands increase, the scale-up model encounters bottlenecks. New systems must be introduced to manage additional data, leading to increased complexity and isolated storage silos. This architecture also struggles with resource allocation inefficiency, as determining the optimal location for workloads becomes increasingly challenging.
RAID technology underpins drive failure protection in scale-up systems. However, RAID does not extend across multiple storage controllers, anchoring the drives to a specific controller and consequently cementing the scalability challenge of this architecture.
Figure 1 – Modular/Scale-up Storage Architecture
As an organization’s data volume grows, completely new systems need to be added to cope with the additional demands. Ultimately, this architecture becomes highly complex to manage. Inefficient resource allocation becomes an issue in deciding where workloads need to reside.
Figure 2 shows the potential for storage system sprawl.
Figure 2 – Modular/Scale-up Storage Silos
The Modern Scale-Out Strategy
In contrast, scale-out storage architectures, particularly those utilizing object storage, offer a dynamic alternative. Constructed with industry-standard servers, storage is linked to each node, reminiscent of Direct Attached Storage (DAS). Object storage software on each node unifies the nodes into a single cluster, creating a pooled storage resource with a unified namespace accessible to users and applications.
Protection against drive failure in a scale-out environment is not reliant on RAID but on RAIN (Redundant Array of Independent Nodes), which offers data resilience across nodes. RAIN supports several data protection methods, including replicas and erasure coding, which mirror RAID’s data safeguarding principles but are optimized for multi-node environments.
Figure 3 – Object/Scale-out Storage Architecture
Scale-Out with Cloudian HyperStore
Cloudian HyperStore exemplifies the scale-out storage solution. HyperStore utilizes object storage technology to enable seamless scalability, providing a storage platform that expands horizontally by adding nodes. Each node addition enhances storage capacity, as well as compute and networking capabilities, ensuring that performance scales with capacity.
HyperStore’s architecture allows for simple integration of new nodes, which the system then incorporates into the existing cluster. Data is intelligently distributed across the new configuration, maintaining performance and reliability without the limitations of traditional scale-up architectures.
In a multi-data center setup, Cloudian HyperStore’s geo-distributed capabilities shine. Nodes can be deployed across various geographical locations, and thanks to HyperStore’s geo-awareness, data can be strategically placed to optimize access speeds. Users access storage through a virtual address, with the system directing requests to the closest or most optimal node. This ensures fast response times and consistent data availability, irrespective of the user’s location.
HyperStore’s innovative approach not only addresses the immediate scalability challenges but also provides a future-proof solution that accommodates the ever-increasing volume and complexity of enterprise data. Its efficient use of resources, simplified management, and robust data protection mechanisms make it a compelling choice for enterprises looking to overcome the traditional hurdles of storage expansion.
In summary, the evolution from scale-up to scale-out storage, epitomized by solutions like Cloudian HyperStore, marks a significant transition in enterprise storage. Organizations can now address their data growth challenges more effectively, with architectures designed for the demands of modern data management.
Just about every organization is evaluating or using cloud in some fashion. When you look at various enterprises, there’s a wide range of deployment options to consider, but one thing is certain: as cloud spend continues to increase, some form of multi-cloud will be part of most enterprise cloud strategies, so it’s essential to have the right storage infrastructure in place to support multi-cloud.
Henry Chu, Director of Solution Management, Cloudian
Just about every organization is evaluating or using cloud in some fashion. When you look at various enterprises, there’s a wide range of deployment options to consider: on-premises private cloud, hybrid using on-premises private cloud and public cloud, colo-services, or a mix of various public clouds. But one thing is certain, that as cloud spend continues to increase, some form of multi-cloud will be part of most enterprise cloud strategies, so it’s essential to have the right storage infrastructure in place to support multi-cloud.
Multi-Cloud Obstacles
What are some of the obstacles of doing multi-cloud? There are quite a lot, but let’s focus on a specific area. Data storage — specifically, object storage offerings across the clouds, as it provides the vast majority of capacity needs for multi-cloud environments. If you don’t have the right object storage solution, it can present significant challenges.
Most customers and cloud applications look for S3 compatibility as it is fast becoming the de facto standard for cloud storage. However, not every provider has an S3 service, and even if a provider does have one, the S3 APIs often are not the same or do not have the same compatibility, depending on where they’re deployed. As a result, APIs and UX differences can impact an organization’s processes and applications.
For example, API and UX differences among S3-compatible storage systems might require that applications and tools in a DevOps environment be changed or rewritten. This can lead to increased development and operational costs, such as those involving code changes to apps or admins having to change their tools to make things work with these incompatible services or APIs.
Managing multi-clouds can be another challenge. Because each provider has its own APIs and tools to manage cloud resources, this raises the question of how you manage a service across multiple clouds.
Finally, there’s the cost of operating across multiple clouds. Some providers impose additional egress charges for moving data out of their cloud, which can make certain operations cost prohibitive. Also, some storage platforms’ methods of providing data replication or availability across multiple clouds can generate additional egress charges.
Cloudian’s Multi-cloud S3-compatible Storage
Going to a multi-cloud deployment provides some inherent benefits:
Data locality: Ability to distribute the data closer to the application, where it’s needed.
Data Availability: Ability to protect your enterprise data by leveraging the hyperscalers as a second location, or use one hyperscaler with another hyperscaler as a DR site.
Cost benefits: Path to reduce TCO by leveraging cost advantages of different clouds.
With Cloudian HyperStore, the benefits are further enhanced. HyperStore provides a cloud-agnostic S3 object storage. Same S3 service, with unified management and access across any cloud deployments. Because it’s fully S3-compatible object storage, HyperStore can also be deployed on-prem and across any/all the major hyperscalers (AWS, Google, Azure).
With Hyperstore, you can have a single namespace and same S3-compatible service across all clouds, giving you the same S3 APIs and UX. It’s worth pointing out that Hyperstore has the most compatible S3 APIs compared with AWS S3. The S3 API is part of HyperStore’s core design, resulting in the highest levels of compatibility. And because S3 is the de facto standard for cloud storage, most — if not all — cloud applications will likely be compatible with HyperStore out of the box.
With HyperStore object storage in a multi-cloud deployment, you can enable cloud services such as Backup-as-a-Service, Archive-as-a-Service and Storage-as-a-Service as well as deploy data lakehouse solutions leveraging data locality from different cloud providers. In addition, HyperStore has the industry-leading S3 Object Lock implementation for data immutability — protecting data across any/all clouds from ransomware.
Broader Benefits of Cloudian HyperStore
With HyperStore, you get a simple but flexible configuration across all clouds.
As mentioned above, HyperStore provides a single namespace across all types of clouds, from on-prem private clouds to hyperscalers, and a single common management interface. And with Cloudian’s HyperIQ, you get single-view-monitoring and analytics.
HyperStore can be deployed in a single region or multi-region configuration, and with multi-region, there’s the option of cross-region replication.
In terms of scale, HyperStore users can start small with just 3 nodes and scale up to an exabyte without interruption
S3 endpoint is flexible in that it can go to a single region, multi-region or even down to a specific data center (DC). Cloudian can also distribute S3 requests to a specific DC or across different regions with its HyperBalance load balancer.
The regions can be comprised of on-prem, AWS, Google, Azure, or any combination.
Cloudian has a wide range of storage policies that are configurable on a per S3 bucket basis. Storage policies define the protection for a bucket, using replication factor or erasure coding. The objects can then be distributed to different DCs or be kept at a single DC.
Additionally, the way HyperStore handles distribution of data across DCs defined by storage policies minimizes egress when writing object data into a HyperStore cluster. HyperStore distributes the PUT requests among each individual node that resides on each public cloud. This provides a more efficient way to replicate data across multiple clouds by using more ingress and minimizing egress. In contrast, a store-and-forward method to replicate data across multiple clouds would use not only ingress but egress for the data that is being replicated, incurring additional egress charges.
As mentioned above, in a multi-region configuration, Cloudian can replicate across the regions with cross-region replication. This means remote sites can be used for DR or data backup and restore at any point in time.
Finally, HyperStore can tier to remote public clouds like AWS, GCP, or Azure even if the remote site does not have HyperStore, providing the option to move metadata and data to public clouds and have bimodal access.
In summary, for any enterprises that are adopting any form of multi-cloud — whether it be on-prem private cloud, hybrid, or any mix of public clouds — Cloudian HyperStore provides the common S3 service in a single namespace across all clouds. With the highest S3 API compatibility, it helps ensure application compatibility with S3 is maintained.
We will be diving further into HyperStore compatibility and other multi-cloud topics in future blogs. In the meantime, see our multi-cloud demos to learn more about the benefits of deploying Cloudian for these environments.
GitHub has traditionally been known as a commonly used cloud service to store, manage and share code using tools like Git. It is this service that’s most familiar to many developers. However, GitHub also has an offering that provides the ability to use GitHub on-premises with GitHub Enterprise Server (GHES) for enterprises that require a solution behind their firewall due to network restrictions or generally want tighter control over their data and access to it.
Henry Chu, Director of Solution Management, Cloudian
GitHub has traditionally been known as a commonly used cloud service to store, manage and share code using tools like Git. It is this service that’s most familiar to many developers. However, GitHub also has an offering that provides the ability to use GitHub on-premises with GitHub Enterprise Server (GHES) for enterprises that require a solution behind their firewall due to network restrictions or generally want tighter control over their data and access to it. GHES includes GitHub Actions and GitHub Packages, both of which can use not only public cloud storage but also on-prem S3-compatible object storage, which is what’s needed for a complete on-prem deployment of GHES. Cloudian HyperStore provides a validated on-prem object storage for GHES with the highest levels of S3 compatibility. In addition, HyperStore can also be deployed across multiple public clouds, providing a distributed S3 service for GHES with a single namespace across multi-cloud infrastructure.
This blog focuses on how to deploy HyperStore with GitHub Actions and GitHub Packages on-prem.
GitHub Actions
GitHub Actions automates CI/CD workflows and are created from building, testing, pull, and deploying requests. Cloudian HyperStore provides the on-prem S3-compataible object storage for GitHub Actions to store data such as artifacts and logs.
Cloudian has validated the necessary S3 operations used by GitHub Actions with HyperStore (see Cloudian’s validation at GHES Storage Partners). Using GitHub’s ghe-storage-test.sh, all storage operations have passed.
To configure GitHub Actions with Cloudian HyperStore, go to GHES Site admin interface.
On Site admin, go to Management console.
At the Management console, go to Applications and Enable GitHub Actions. Under Artifact & Log Storage, choose Amazon S3.
Enter the following fields:
AWS Service URL: Enter the S3 endpoint configured for your HyperStore Cluster.
AWS S3 Bucket: Enter the name of the bucket to be used for GitHub Actions
AWS S3 Access Key: Enter the access key for the HyperStore user for the given bucket
AWS S3 Secret Key: Enter the secret key for the HyperStore user for the given bucket
Click on Test storage settings to validate the configuration. Then save the settings.
GitHub Packages
GitHub Packages gives you a safe way to publish and share application packages within your organization. With Cloudian HyperStore, you can achieve a complete on-prem deployment.
To configure GitHub Packages with HyperStore, go to Management console and then to Packages. Enable GitHub Packages.
Choose Amazon S3 for your storage. Enter the following fields:
AWS Service URL: Enter the S3 endpoint configured for your HyperStore Cluster.
AWS S3 Bucket: Enter the name of the bucket to be used for GitHub Packages.
AWS S3 Access Key: Enter the access key for the HyperStore user for the given bucket
AWS S3 Secret Key: Enter the secret key for the HyperStore user for the given bucket
Click on Test storage settings to validate the configuration and then save the settings.
Summary
With GitHub Enterprise Server and Cloudian HyperStore, enterprises now have a solution to store, manage, and share code with full control behind the security of their firewall. HyperStore provides the S3-compatible object storage on-prem (or distributed over multi-cloud) for GitHub Actions, a solution for CI/CD workflows. Similarly, HyperStore can also be used as a storage target for GitHub Packages, a repository for application packages.
Organizations today face the challenge of not only storing large data volumes but also being able to ingest, access and analyze the data to get insights on demand. That’s why they’re turning to observability solutions backed by scalable S3-compatible data lakes.
Path to Data Insights – Data Observability Platform with an S3-Compatible Data Lake
More than 90% of all data in the world was generated in just the last few years, and, according to IDC, the amount of data generated annually is expected to nearly triple from 2020 to 2025. This incredible growth presents the challenge of not only storing large data volumes but also, more importantly, of being able to ingest, access and analyze the data to get insights on demand. That’s why organizations are turning to data observability solutions backed by scalable S3 data lakes to break the silos and get business insights.
Monitoring vs Observability
Let’s first distinguish between monitoring and observability.
Monitoring refers to the processes and systems used by organizations to flag data for performance degradation and/or potential security breaches. Organizations can then configure these systems to send alerts and also automate the types of responses to certain events. Useful as it is, monitoring typically stays at one layer, either application or infrastructure and is only a partial solution.
Observability, on the other hand, provides full visibility into the health and performance of each layer of your environment. It starts with the capability to connect and ingest data from multiple sources into multiple tools and gives IT teams full visibility into their environment, from applications to infrastructure assets. Organizations are then able to observe their entire IT environment together and get insights to forecast future trends and outcomes which helps save time and money.
The Cloudian-Cribl Observability Platform
Cribl—a leading data analytics company and a key Cloudian technology alliance partner—has developed cutting-edge technology to solve the challenge of ingesting, managing and analyzing data more productively as well as efficiently. Cribl’s Stream product is an observability pipeline that connects to various sources of data, like networks, servers, applications, and software agents, and centralizes all of your observability data with full fidelity into an S3 data lake with Cloudian HyperStore object storage. This forms a modern observability platform based on a scale-out S3-compatible data lake designed for managing massive amounts and varieties of data, giving IT teams full control over every aspect of the data. The data is stored in HyperStore and always available for search and analysis. Cribl then allows customers to Replay (Cribl function) the data in Cloudian – applying filters and transformations as required – and feed it to higher level analytic tools like Splunk, Elastic and others.
The observability solution is also hybrid cloud-compatible, enabling organizations to reduce costs by having both on-prem and cloud assets simultaneously. Together, the solution built on Cribl and Cloudian lets you parse, restructure, and enrich data in flight – ensuring that you get the right data, where you want, and in the format you need. This provides organizations the opportunity to discover and understand their dynamic environments in real time and use the resulting data insights to make better informed decisions.
To learn more about the newly minted Cloudian-Cribl partnership how it can help you, register for the upcoming Cribl-Cloudian webinar on Nov. 9, 8am PST. You can also read more about the Cribl-Cloudian solution here.
The ability to create and manage multiple control plane configuration sets (or storage policies) is needed to support multiple tenants and use cases in an object storage system.
Supporting Multiple Tenants with Bucket-Level Object Storage Policies
The ability to create and manage multiple control plane configuration sets (or storage policies) is needed to support multiple tenants and use cases in an object storage system. Cloudian’s HyperStore object storage software supports multiple, bucket-level storage policies as a fundamental architectural principle. The following sections describe some design choices we made in how to manage and use those storage policies.
Why Bucket-Level Storage Policies
Figure 1: Multiple, bucket-level storage policies
In object storage systems (e.g., Amazon S3), there are two main concepts to organize data: objects and buckets. Objects, such as text files, images, videos, etc., are the data to be stored. Buckets are containers for objects used to group objects together. When creating a new object, the user specifies the bucket to use. Each object belongs to exactly one bucket. Applying an operation to a bucket can affect all the objects in that bucket. For example, access control settings on a bucket dictate user access to the objects in the bucket.
In addition to the data plane of operations on objects and buckets such as storing an object, there are control plane operations that determine how that data is managed on the system. When the object storage system is managed directly by the user, the user must determine the control plane configuration settings. For example, a replication policy on the number of object replicas stored can be set for the system. There are many other control plane configurations for data, including compression type, encryption, geo-distribution across availability zones and regions, data consistency level, and more.
Legacy object storage systems support a single, static control plane configuration for the data. However, for users that want to use objects for different purposes, a single configuration is insufficient. For example, the same user may have a use case that requires strong consistency, such as data used for transactions, while another use case – such as historical log data – can be stored with eventual consistency. Another common situation is that the storage system may have multiple tenants where each tenant has different requirements on data durability and availability. In addition, both the use cases and the tenants may change over time. Having the option to create new storage policies to match the changing use of the storage system is critical.
Assigning a Storage Policy to Data
One of the first questions we addressed was how should a storage policy be assigned to data. Because the primary concepts of an object storage system are simply an object and a bucket, those two concepts were considered. If object granularity were used, then each object can be assigned to its own storage policy. This can be set in an HTTP header when the object is uploaded, e.g, “x-amz-storage-policy: eu4policy”, but this requires the client to know the different storage policies. It also makes comprehending the different storage policies more difficult because each object, even different versions of the same object, may have different storage policies.
Alternatively, assigning a storage policy to a bucket is a good cognitive fit because buckets are already used to group objects together. Then the workflow is when a bucket is created, a storage policy is selected for the bucket and applied to all objects to be created in the bucket. A user can then split their data by storage policies by selecting a bucket and creating a new bucket if a different storage policy is warranted. These considerations made it clear that a per-bucket or bucket-level storage policy was the best choice.
The Configuration Content of a Storage Policy
Some control plane configuration settings were mentioned earlier. The tradeoff was to avoid having an overly verbose and complex policy by including every setting vs. providing enough control to the user to be useful. In this case, user feedback was needed to understand how they wanted to use multiple storage policies. We interviewed several existing users for this purpose. Some configuration settings were unanimously cited, including replication strategy (replicas or erasure coding, number of fragments, geo-distribution) and data consistency level (read, write, multiple availability zones). One interesting learning was that users wanted flexibility to handle use cases that were not yet known. As a result, the set of configuration settings grew over time as more control to handle new use cases was requested.
Figure 3: Creating a new storage policy
Managing a Storage Policy
When it came to managing a storage policy, considerations included how to create, view, edit, and delete storage policies, how to manage access, and how to present this capability in an easy-to-use, functional user experience. An HTTP API was first designed that provided all the functionality to manage both a single storage policy and multiple storage policies. Then various iterations of a user interface were developed. The user interface was allowed to only use the existing API. This ensures that users can develop their own software to use the API and have full functionality.
Bringing It All Together
An illustrative example of multiple, per-bucket storage policies is a hub-and-spoke model where the hub is a central data center and multiple satellite offices are connected to the hub by the spokes as depicted in Figure 4. A large satellite office (DC1) is configured with a storage policy that stores 3 replicas of each object in the satellite office data center and 1 replica in the central data center (DC0). A small satellite office (DC2) is configured with a storage policy with 1 replica in the satellite office and 1 replica in the central data center.
Figure 4: Storage policies for a hub-and-spoke model
Next Steps
The bucket-level storage policies functionality has been an important discriminator of Cloudian’s HyperStore object system. It “future-proofs” the system since new users and groups and new use cases can be accommodated by adding new storage policies to a running system.
Future work includes how much flexibility is allowed to change existing storage policies that may already apply to millions of objects and to associate different billing rates to different storage policies.
Microsoft and Cloudian enable organizations to leverage the benefits of public cloud while keeping some infrastructure, applications and data on-premises, behind the firewall and fully under the organization’s control.
Meeting Hybrid Cloud Demands: Microsoft AzureStack HCI and Cloudian HyperStore
Over the last two years, hybrid cloud has become the dominant IT deployment model, with 82% of IT leaders saying they’ve adopted it in a Cisco report earlier this year.[1] It enables organizations to leverage the benefits of public cloud while keeping some infrastructure, applications and data on-premises, behind the firewall and fully under the organization’s control. Reflecting the increasing adoption of hybrid cloud, global hyperscalers have introduced new services to meet the demand and ensure a seamless experience across public and private clouds. Here we take a look at the Microsoft AzureStack HCI service and how Cloudian’s HyperStore object storage works with the service.
According to Microsoft, “AzureStack HCI is a hyperconverged infrastructure host platform integrated with Azure. Run Windows and Linux virtual machines on-premises with existing IT skills and familiar tools. Delivered as an Azure subscription service, Azure Stack HCI is always up-to-date and can be installed on your choice of server hardware.”
Cloudian HyperStore, a leading scale-out storage system, has been validated to work with Azure Stack HCI, enabling customers to store and protect large amounts of unstructured data on prem and use the Azure public cloud for real-time, on-demand computing power, which is more cost effective than buying additional hardware.
HyperStore employs policy-based tools to replicate or tier data to Azure for offsite disaster recovery, capacity expansion or data analysis in the cloud. HyperStore offers limitless scalability, multi-tenancy and military-grade security. This includes the ability to isolate storage pools using local and remote authentication methods such as Password, AD, LDAP, IAM and certificate-based authentication.
Deploying Cloudian HyperStore on Azure Stack HCI provides the following key benefits:
Turnkey HCI solution – network, compute, storage and virtualization
Hybrid cloud readiness – seamless movement of data across on-prem and public cloud environments
Unified view of data – a single namespace across multiple locations
Reduced operational costs – savings on data egress and bandwidth charges
To learn more about the Cloudian HyperStore-Azure Stack HCI hybrid cloud solution, go to cloudian.com/microsoft/#azure.
The modernization of the data analytics architecture started in the cloud, but not everyone is able to or willing to move their data to the cloud, for data gravity, security, and/or compliance reasons. Organizations can now implement an S3 data lakehouse and get the same benefits with greater control.
Amit Rawlani, Director of Solutions & Technology Alliances, Cloudian View LinkedIn Profile
On-prem S3 Data Lakehouse for Modern Analytics and More
Data Lakehouse Origin
The modernization of the data analytics architecture started in the cloud. This was driven by the limits of traditional data warehouses with a conventional appliance-based approach, which could not provide the needed scalability, was cumbersome to work with and expensive, and could only serve one use case. In response, companies such as Snowflake and Databricks took the traditional OLAP operations and showed the benefits of combining the flexibility, cost-efficiency, and scale of a data lake built on cloud storage (based on the S3 API) with the data management and ACID transactions of a data warehouse, thereby giving us the modern data lakehouse.
However, not everyone is able to or willing to move their data to the cloud, for data gravity, security, and/or compliance reasons. Customers – especially enterprise customers – have started replicating the same architecture that Snowflake pioneered within their own data centers and/or in hybrid cloud configurations. Specifically, by using S3-compatible object storage platforms like Cloudian HyperStore, customers can now implement an S3 data lakehouse and get the same efficiencies with greater control.
The Many Benefits of a Data Lakehouse Architecture
An on-prem data lakehouse solution offers the same cloudification of the data analytics environment, but behind the security of users’ firewalls. This gives organizations full control to implement the right security protocols, compliance measures, and audit-logging for their needs.
In addition to providing public cloud-like scalability, the data lakehouse architecture also gives customers the ability to scale the data lake (storage) independent of the compute, a big difference from the shared-everything architectures that bogged down the big data world a few years ago.
Standardization on the S3 API — the de facto storage standard of the cloud — enables enterprises to continue to build and reuse applications already built for the cloud with their on-prem data lakehouse. Standardization also allows for use cases beyond analytics, such as a repository for Splunk data and immutable backup storage for ransomware protection — generally a repository for all unstructured data (media, images, videos, etc.) — and all supported in the same S3 data lakehouse.
Organizations face a range of challenges in managing and protecting their data, providing new market opportunities for service providers. Cloudian’s enhanced MSP program ensures MSP partners are well-positioned to capitalize on these opportunities by delivering greater value-add to their customers and driving increased growth and profit.
Cloudian Enhances MSP Partner Program
Organizations face a range of challenges in managing and protecting their data. Unstructured data is growing more than 50% annually, and users expect access to their files anytime and anywhere. At the same, ransomware continues to pose a major threat — attacks rose 92.7% in 2021 compared to 2020* — showing how important it is to increase data security protections on different levels. In addition, regulatory requirements such as GDPR and HIPAA, along with concerns about data sovereignty, are imposing new constraints on how data is stored and handled. Finally, IT budgets are under increasing pressure, and hiring needed IT expertise is often difficult in today’s labor market.
All of this creates opportunities for Managed Service Providers (MSPs) to help customers address these challenges, and Cloudian’s newly enhanced MSP partner program ensures our partners are well-positioned to capitalize on these opportunities.
Providing a Leading S3 Data Management Platform
Cloudian’s HyperStore object storage solution offers many benefits, including:
Feature-rich management tool set – Integrated tools such as billing and quality of service controls make it easy for MSPs to manage their business and service delivery.
Secure multi-tenancy – Keeping one customer’s data separated from others while leveraging a shared infrastructure is a must-have feature for any cloud storage service. HyperStore allows multiple users and applications to share the same infrastructure while ensuring no-compromise data protection. Role-Based Access Controls (RBAC) also give MSPs’ customers management access within their environments.
Customized SLAs – HyperStore manages data at the bucket level, allowing MSP partners to build different storage and protection policies based on data durability, efficiency, and cost.
Native S3 API compatibility – HyperStore is fully S3 compatible. That means it supports all S3-compatible applications and can provide seamless data management across on-premises and public cloud environments.
Military-grade security – Features include Object Lock-based data immutability for ransomware protection, b, encryption for data at rest and in flight, and RBAC/IAM access policies and authentication. Certifications include Common Criteria EAL-2, FIPS 140-2, SEC Rule 17a-4(f), FINRA Rule 4511 and CFTC Rule 1.31(c)-(d).
Limitless, modular scalability – Unlike many other object storage providers requiring users to over-provision, Cloudian lets you start small and grow without limitations. As more capacity is needed, you can non-disruptively add additional nodes or even new sites, and that capacity becomes part of the available storage pool.
Global data fabric, single namespace – With HyperStore, you can manage data as a single storage pool, no matter where the data resides. That means petabytes of capacity can be spread across regions and data centers and still be managed from a central location.
Cost-effective capacity – HyperStore offers cost savings of up to 70% compared to traditional disk-based storage systems, enabling users to add significantly more capacity for the same budget.
Foundation for High-Value Services
Cloudian’s MSP Partner Program enables MSPs to create innovative offerings for various high-value use cases, either stand-alone or in conjunction with Cloudian’s technology partners. These services include:
Storage-as-a-Service (STaaS) – Provide additional storage capacity on a subscription or consumption (VMware VCPP) basis to help customers address their growing volumes of data. Seamlessly integrate with VMware Cloud Director.
Backup-as-a-Service (BaaS) – Deploy HyperStore as the backup target for leading backup platforms such as Veeam, Commvault, Rubrik, and Veritas.
Ransomware Protection-as-a-Service (RPaaS) – Leverage HyperStore’s Object Lock-based data immutability to prevent cybercriminals from encrypting or deleting data, thereby enabling quicky recovery of the unchanged data in the event of a ransomware attack, without paying ransom.
Archive-as-a-Service (AaaS) – With HyperStore’s limitless scalability and data durability (up to 14 nines), provide an ideal long-term data repository.
Disaster Recovery-as-a-Service (DRaaS) – Help customers avoid the risks of the business and organizational disruptions resulting from disasters by keeping a copy of their data offsite.
Big Data-as-a-Service (BDaaS) – Leveraging Cloudian’s rich metadata tagging, facilitate the application of machine learning and analytics to large data sets, enabling new insights, discoveries, and operational efficiencies.
Containers-as-a-Service (CaaS) – With Cloudian’s fully native S3 compatibility, provide persistent, enterprise-grade storage for Kubernetes environments.
Office 365-Backup-as-a-Service (ObaaS) – Help your clients address the urgent need to protect their Office 365 data with HyperStore as a secure backup repository.
Besides HyperStore, MSP partners can also incorporate Cloudian’s HyperIQ, HyperFile, and HyperBalance solutions into their service offerings. In addition, MSP program partners get access to Cloudian training, technical support, and collateral.
MSP Partner Testimonials
Here is just a sampling of what partners say about our solutions:
“Cloudian and VMware are helping us compete with the largest public cloud providers on a level playing field.” – Peter Zafiris, Senior Infrastructure Engineer, AUCloud (Read more about AUCloud and Cloudian here.)
“Our Cloudian partnership has enabled us to pursue new market opportunities, deliver enhanced value to our customers and drive more profitable growth.” – Adam Svoboda, principal cybersecurity strategist, Eagle Technologies (Read more about Eagle Technologies and Cloudian here.)
Amazon Simple Storage Service (Amazon S3) is an object storage solution that provides data availability, performance, security and scalability. Organizations from all industries and of every size may use Amazon S3 storage to safeguard and store any amount of information for a variety of use cases, including websites, data lakes, backup and restore, mobile applications, archives, big data analytics, IoT devices, and enterprise applications.
What Is AWS S3 Bucket?
Amazon Simple Storage Service (Amazon S3) is an object storage solution that provides data availability, performance, security and scalability. Organizations from all industries and of every size may use Amazon S3 storage to safeguard and store any amount of information for a variety of use cases, including websites, data lakes, backup and restore, mobile applications, archives, big data analytics, IoT devices, and enterprise applications.
To retain your information in Amazon S3, you use resources called objects and buckets. A bucket is a container that houses objects. An object contains a file and all metadata used to describe the file.
To retain an object in Amazon S3, you develop a bucket and upload the object into it. Once the object is within the bucket, you may move it, download it, or open it. When you don’t require the bucket or object any longer, you can discard them to trim back on your resources.
This is part of an extensive series of articles about S3 Storage.
How to Use an Amazon S3 Bucket
An S3 customer starts by establishing a bucket in the AWS region of their choosing and assigns it a unique name. AWS suggests that customers select regions that are geographically close to them in order to minimize costs and latency.
After creating the bucket, the user chooses a storage tier based on the usage requirements for the data—there are various S3 tiers ranging in terms of price, accessibility and redundancy. A single bucket can retain objects from distinct S3 storage tiers.
The user may then assign particular access privileges regarding the objects retained in the bucket using various mechanisms, including bucket policies, the AWS IAM service, and ACL.
An AWS customer may work with an Amazon S3 bucket via the APIs, the AWS CLI, or the AWS Management Console.
Before you can store content in S3, you need to open a new bucket, selecting a bucket name and Region. You may also wish to select additional storage management choices for your bucket. Once you have configured a bucket, you can’t modify the Region or bucket name.
The AWS account that opened the bucket remains the owner. You may upload as many objects as you like to the bucket. According to the default settings, you can have as many as 100 buckets for each AWS account.
S3 lets you create buckets using the S3 Console or the API.
Keep in mind that buckets are priced according to data volume stored in them, and other criteria. Learn more in our guide to S3 pricing
The bucket name must be unique, begin with a number or lowercase letter, be between 3-63 characters, and may not feature any uppercase characters.
4. Select the AWS Region for the bucket. Select a Region near you to keep latency and cost to a minimum and to address regulatory demands. Keep in mind there are special charges for moving objects outside a region.
5. In Bucket settings for Block Public Access, specify if you want to allow or block access from external networks.
6. You can optionally enable the Object Lock feature in Advanced settings > Object Lock.
7. Select Create bucket.
What Is S3 Bucket Policy?
S3 provides the concept of a bucket policy, which lets you define access permissions for a bucket and the content stored in it. Technically, it is an Amazon IAM policy, which employs a JSON-based policy language.
For instance, policies permit you to:
Enable read access for unknown users
Restrict a particular IP address from accessing the bucket
Place a limit on access to a particular HTTP referrer
Require multi-factor authorization
S3 Bucket URLs and Other Methods to Access Your Buckets
You can perform almost any operation using the S3 console, with no need for code. However, S3 also provides a powerful REST API that gives you programmatic access to buckets and objects. You can reference any bucket or the objects within it via a unique Uniform Resource Identifier (URI).
Amazon S3 provides support for path-style and virtual-hosted-style URLs to gain access to a bucket. Given that buckets are accessible to these URLs, it is suggested that you establish buckets with bucket names that are DNS-compliant.
Virtual-Hosted-Style Access
In a virtual-hosted-style request, the bucket name is a component of the domain name within the URL.
Amazon S3 virtual-hosted-style URLs employ this format:
https://bucket-name.s3.Region.amazonaws.com/key name
For example, if you name the bucket bucket-one, select the US East 1 (Northern Virginia) Region, and use kitty.png as your key name, the URL will look as follows:
https://s3.Region.amazonaws.com/bucket-name/key name
For example, if you created a bucket in the US East (Northern Virginia) Region and named it bucket-one, the path-style URL you use to access the kitty.jpg object in the bucket will look like this:
Certain AWS services need you to specify an Amazon S3 bucket via S3://bucket, where you will need to follow this format:
S3://bucket-name/key-name
Note that when employing this format the bucket name does not feature the AWS Region. For example, a bucket called bucket-one with a kitty.jpg key will look like this:
AWS provides various tools for Amazon S3 buckets. An IT specialist may enable different versions for S3 buckets to retain every version of an object when an operation is carried out on it, for example a delete or copy operation. This may help stop IT specialists from accidentally deleting an object. Similarly, when creating a bucket, a user can establish server access logs, tags, object-level API logs, and encryption.
S3 Transfer Acceleration can assist with the execution of secure and fast transfers from the client to an S3 bucket via AWS edge locations.
Amazon S3 provides support for different alternatives for you to configure your bucket. Amazon S3 offers support for subresources so you can manage and retain the bucket configuration details. You can employ the Amazon S3 API to manage and develop these subresources. You may also utilize the AWS SDKs or the console.
These are known as subresources since they function in the context of a certain object or bucket. Below lists subresources that let you oversee bucket-specific configurations.
cors (cross-origin resource sharing): You may configure your bucket to permit cross-origin requests.
event notification: You may permit your bucket to alert you of particular bucket events.
lifecycle: You may specify lifecycle regulations for objects within your bucket that feature a well-outlined lifecycle.
location: When you establish a bucket, you choose the AWS Region where you want Amazon S3 to develop the bucket. Amazon S3 retains these details in the location subresources and offers an API so you can gain access to this information.
logging: Logging lets you monitor requests for access to the bucket. All access log records give details regarding one access request, including bucket name, requester, request action, request time, error code, and response status.
object locking: Enables the object lock feature for a bucket. You may also wish to configure a default period of retention and mode that applies to the latest objects that are uploaded to the bucket.
policy and ACL (access control list): Both buckets and the objects stored within them are private, unless you specify otherwise. ACL and bucket policies are two ways to grant permissions for an entire bucket.
replication: This option lets you automatically copy the content of the bucket to additional buckets, within the Amazon Region. Replication is asynchronous.
requestPayment: By default, the AWS account that sets up a bucket also receives bills for requests made to the bucket. This setting lets the bucket creator pass on the cost of downloading data from the bucket to the account downloading the content.
tagging: This setting allows you to add tags to an S3 bucket. This can help you track and organize your costs on S3. AWS shows the tags on your charges allocation report, with costs and usage aggregated via the tags.
transfer acceleration: Transfer acceleration enables easy, secure and fast movement of files over extended distances between your S3 bucket and your client. Transfer acceleration leverages the globally distributed edge locations via Amazon CloudFront.
versioning: Versioning assists you when recovering accidental deletes and overwrites.
website: You may configure the bucket for static website hosting.
Best Practices for Keeping Amazon S3 Buckets Secure
AWS S3 Buckets may not be as safe as most users believe. In many cases, AWS permissions are not correctly configured and can expose an organization’s AWS S3 buckets or some of their content.
Although misconfigured permissions are by no means a novel occurrence for many organizations, there is a specific permission that entails increased risk. If you allow objects to be public, this establishes a pathway for cyberattackers to write to S3 buckets that they don’t have the correct permissions to access. Misconfigured buckets are a major root cause behind many well-known attacks.
To protect your S3 buckets, you should apply the following best practices.
Block Public S3 Buckets at the Organization Level
Assign AWS accounts for public S3 utilization and stop all other S3 buckets from accidentally becoming public by putting in place S3 Block Public Access. Employ Organizations Service control policies (SCPs) to ensure that the Block Public Access setting is not alterable. S3 Block Public Access offers a degree of safety that functions at the level of the account and also on single buckets, encompassing those that you develop in the future.
You retain the capacity to prevent existing public access—irrespective of whether it was specified by a policy or an ACL—and to make sure that public access is not given to items you newly create. This provides only specific AWS accounts with public S3 buckets and stops all other AWS accounts.
Implement Role-Based Access Control
Outline roles that cover the access needs of users and objects. Make sure those roles have the least access needed to carry out the job so that if a user’s account is breached, the damage is kept to a minimum.
AWS security is founded on AWS Identity and Access Management (IAM) strategies. A principal is an identity that may be validated, for example, with a password. Roles, users, applications, and federated users (from separate systems) may all be principals. When a validated principal requests an entity, resource, service, or a different asset, verification begins.
Verification policies determine what access the principal has to the resource being requested. Approval is given based on resource-based methods or identity. Matching each validated principal with each validated policy will ascertain if the request is permitted.
Another data security methodology is splitting or sharing data into different buckets. For instance, a multi-tenant application could require separate Amazon S3 buckets for every tenant. You can use another AWS tool, Amazon VPC, which grants your endpoints secure access to sections of your Amazon S3 buckets.
Encrypt Your Data
Even with your greatest efforts, it remains good practice to assume that information is always at risk of being exposed. Given this, you should use encryption to stop unauthorized individuals from using your information if they have managed to access it.
Make sure that your Amazon S3 buckets are encrypted during transit and while sitting on the server. If you just have a single bucket, this is likely not complex, but if buckets are being developed dynamically, it may be difficult to keep track of them and manage encryption appropriately.
On the server side, Amazon S3 buckets support encryption, but this has to be enabled. Once encryption is turned on, the information is encrypted at rest. Encrypting the bucket will make sure that any individual who manages to access the data will require a password (key) to decrypt the data.
For transport security, HTTPS is used to make sure that information is encrypted from one end to another. Every additional version of Transport Layer Security (TLS) ensures that the protocol is more secure and does away with out-of-date, now insecure, encryption methods.
S3-Compatible Storage On-Premises with Cloudian
Cloudian® HyperStore® is a massive-capacity object storage device that is fully compatible with Amazon S3. It allows you to easily set up an object storage solution in your on-premises data center, enjoying the benefits of cloud-based object storage at much lower cost.
HyperStore can store up to 1.5 Petabytes in a 4U Chassis device, allowing you to store up to 18 Petabytes in a single data center rack. HyperStore comes with fully redundant power and cooling, and performance features including 1.92TB SSD drives for metadata, and 10Gb Ethernet ports for fast data transfer.
HyperStore is an object storage solution you can plug in and start using with no complex deployment. It also offers advanced data protection features, supporting use cases like compliance, healthcare data storage, disaster recovery, ransomware protection and data lifecycle management.
As your business expands, you have to manage isolated but rapidly growing pools of data from various sources, which are used for a variety of business processes and applications. Nowadays, many organizations grapple with a fragmented storage portfolio that slows down innovation and adds complexity to an organization’s applications. Object storage can help your organization break down these silos. It provides cost-effective, highly scalable storage that can retain any type of data in its original format.
Object storage is highly suitable for the cloud as it is flexible, elastic and can be more easily scaled into many petabytes to support indefinite data growth. The architecture manages and stores data as objects, as opposed to block storage, which relates to data as logical volumes, blocks and files storage, where data is stored in hierarchical files.
Let’s review the object storage offerings by some of the world’s leading cloud providers: Amazon Web Services, Microsoft Azure, Google Cloud, and IBM Cloud.
AWS Object Storage
AWS provides a distinct variety of storage classes for different use cases. Amazon S3 is the main object storage platform of AWS, with S3 Standard-IA providing cool storage, and Glacier providing cold storage:
Amazon S3 Standard—this is the storage choice for information that is often accessed, and is great for numerous use cases including dynamic websites, cloud applications, content distribution, data analytics and gaming. It delivers high throughput as well as low latency.
Amazon S3 Standard-Infrequent Access (Amazon S3 Standard—IA)—this is a storage alternative for data which is accessed less often, such as disaster recovery and long-term backups.
Amazon Glacier—this highly durable storage system is optimized for data that is not often accessed, or “cold” data, such as end-of-lifecycle data kept for compliance and regulatory backup purposes. Data is archived for long-term storage, and is immutable and encrypted.
Azure Object Storage
Microsoft offers Azure Blob Storage for object storage in the cloud. Blob storage is suited to storing any form of unstructured data, such as binary or text. This includes videos, images, documents, audio and more. Azure storage offers high-quality data integrity, flexibility and mutability.
Blob storage is employed for serving documents or images directly to a browser, for retaining files for distributed access, streaming audio and video, writing to log files, disaster recovery, storing data for restore and backup, and archiving, so it can be analyzed by an Azure-hosted or on-premises service.
Azure has several storage tiers, including:
Hot access tier— for information that is in or anticipated to be in active use and staged for processing and subsequent migration to the Cool storage tier.
Cool access tier—for data that is intended to stay in the Cool tier for more than 30 days. This includes disaster recovery datasets and short-term backup, media content that is older and intended to be immediately available when drawn on and large data sets.
Archive access tier—for data which will stay in the Archive tier for more than 180 days, and which can tolerate hours of retrieval latency.
Note: The Archive storage tier is not accessible at the storage account level, but only at the blob level. Azure also provides a Premium tier, which is for workloads that need consistent and fast response times.
Google Cloud Storage
Google Cloud Storage (GCS) provides united object storage for all workloads. It has four classes for backup and archival storage and high-performance object storage. All four classes provide high durability and low latency:
Hot (high-performance) storage—GCS provides regional and multi-regional storage for high-frequency access information.
Multi-regional storage—allows for the storing of information that is often accessed around the world, including streaming videos, serving website content, or mobile and gaming applications.
Regional storage—allows for frequent access to information in the corresponding region of Google Compute Engine instance or Google Cloud DataProc, for example data analytics.
Nearline (cool) storage—for data that only needs to be accessed less than once a month, but several times a year. Suitable for backups and long-tail multimedia content.
Coldline (cool) storage—for data that only needs to be accessed less than once a year. Suitable for archival data and disaster recovery.
IBM Cloud Object Storage
IBM Cloud provides scalable and flexible cloud storage with policy-driven archive abilities for unstructured data. This cloud storage service is intended for data archiving, for example for the long term retention of data that is infrequently accessed, including for mobile and web applications, and for backup and analytics.
IBM has four storage-class tiers integrated with an Asperaâ high-speed information transfer option. This allows for the easy transfer of data from and to Cloud Object Storage, and query-in-place functionality.
IBM Cloud Object Storage class tiers:
Standard storage—for active workloads that need high performance and low latency, and data that requires frequent and multiple access in a month. Usage scenarios are for example, active content repositories, analytics, mobile streaming and web content, collaboration and DevOps.
Vault storage—for less active workloads which need real-time, on-demand access but only infrequently, up to once a month. Use cases include digital asset retention and backup.
Cold vault—for cold workloads, where data needs on-demand, real-time access when needed but is mainly archived. For example, data that is accessed several times a year. Common use cases involve long-term backup, large data set preservation such as older media content and scientific data.
Flex storage—this class tier is utilized for dynamic workloads (combining cold and hot workloads) and data based on access patterns. Typical use cases include cognitive workloads, cloud-native analytics and user-generation applications.
Cloud Object Storage Pros and Cons
The following are some of the key advantages and disadvantages of object storage in the cloud.
Cloud Object Storage Pros
The key advantages of object storage include:
Data is highly distributed, which ensures it is more resilient to hardware failures or disasters. This way, it is available even if various nodes fail.
Objects are kept in a flat address space, which minimizes complexity and scalability issues.
Data protection is built into this architecture in the form of erasure coding or replication technology.
Object storage is most suitable for cloud storage and static data. Common use cases for object storage include archiving and cloud backup—the technology functions best with data that is more frequently read than written to.
Object storage has developed to the point where it scales at the exabyte level and represents trillions of objects. The use of VMs or commodity hardware enables nodes to be added easily, with the disk space being used more efficiently.
Object storage systems, via the use of object IDs (OIDs) or identifiers, can gain access to any piece of data without knowing on which physical storage device, directory, or file system it resides on. The abstraction lets object storage devices operate with storage hardware configured in distributed node architecture. This way, processing power can scale together with data storage capacity.
I/O requests don’t need to pass via a central controller, allowing for a true global storage system for large amounts of data overseen by objects, physically kept anywhere, and retrieved through the internet or a WAN.
Cloud Object Storage Pros
The key disadvantages of object storage include:
Object storage systems are not steady enough for real-time systems, including transactional databases. An undesirable use case for object storage is an environment or application with a high transactional rate.
Object storage doesn’t guarantee that read requests will produce the most up-to-date version of the data.
This technology isn’t alway appropriate for applications that have high performance demands.
Cloud-based storage often ends up being more expensive because you need to pay for storage on an ongoing basis. With on-premises equipment you pay once and the storage is yours.
Bring Object Storage On-Premises with Cloudian
Cloudian® HyperStore® is a massive-capacity object storage device that is fully compatible with Amazon S3. It allows you to easily set up an object storage solution in your on-premises data center, enjoying the benefits of cloud-based object storage at much lower cost.
HyperStore can store up to 1.5 Petabytes in a 4U Chassis device, allowing you to store up to 18 Petabytes in a single data center rack. HyperStore comes with fully redundant power and cooling, and performance features including 1.92TB SSD drives for metadata, and 10Gb Ethernet ports for fast data transfer.
HyperStore is an object storage solution you can plug in and start using with no complex deployment. It also offers advanced data protection features, supporting use cases like compliance, healthcare data storage, disaster recovery, ransomware protection and data lifecycle management.
The threat of ransomware should be thought of as serious problem for all enterprises. According to an annual report on global cyber security, there were 304 million ransomware attacks worldwide in 2020 — a 62% increase from 2019. While most IT organizations are aware of the continuously rising threat of ransomware on traditional applications and infrastructure, modern applications running on Kubernetes are also at risk. The rapid rise of critical applications and data moving into Kubernetes clusters has caught the attention of those seeking to exploit what is perceived to be a new and emerging space. This can leave many organizations ill prepared to fight back.
Kubernetes Vulnerabilities
Kubernetes itself and many of the most common applications that run in Kubernetes are open-source products. Open-source means that the underly code that makes up the applications is freely available for any to review and find potential vulnerabilities. While not overly common, open-source products can often lead to exploitable bugs being discovered by malicious actors. In addition, misconfigured access controls can unintentionally lead to unauthorized access to applications or even the entire cluster. Kubernetes is updated quarterly, and some applications as often as every week, so it’s crucial for organizations to stay up to date with patching.
Surprisingly, many organizations that use Kubernetes don’t yet have a backup and recovery solution in place — which is a last line of defense against an attack. As ransomware becomes more sophisticated, clusters and applications are at risk of being destroyed, and without a means to restore them, you could suffer devastating data and application loss in the case of an attack.
What to Look for In a Kubernetes Ransomware Protection Platform
When looking to an effective defense against ransomware in your K8s environment, think about these four core capabilities:
Backup integrity and immutability: Since backup is your last line of defense, it’s important that your backup solution is reliable, and it’s critical to be confident that your backup target storage locations contain the information you need to recover applications in case of an attack. Having guaranteed immutability of your backup data is a must.
High-performance recovery: No one wants to pay a ransom because it was faster to unencrypt your data than recover it from your backup system. The ability to work quickly to recover resources is critical, as the cost of ransom typically increases over time. Being confident that your recovery performance can meet target requirements even as the amount of data grows over time.
Operational Simplicity: Operations teams must work at scale across multiple clusters in hybrid environments that span cloud and on-premises locations. When you’re working in a high-pressure environment following a ransomware attack, simplicity of operations become paramount.
Cloudian and Kasten by Veeam Have the Solution
Kasten By Veeam and Cloudian have teamed to bring a truly cloud native approach to this mission critical problem. The Kasten K10 data management software platform has been purpose-built for Kubernetes. K10’s deep integrations with Kubernetes distributions and cloud storage systems provide for protection and mobility of your entire Kubernetes application. Cloudian’s HyperStore is an enterprise-grade S3-compatible object storage platform running in your data center. Cloudian makes it easy to use private cloud storage to protect your Kubernetes applications with a verified integration with Kasten. With native support of the cloud standard S3 API, including S3 Object Lock data immutability, Kasten and Cloudian offer seamless protection for modern applications at up to 70% less cost than public cloud.
Fast recovery: Cloudian provides a local, disk-based object storage target for backing up modern apps using Kasten K10 over your local, high-speed network. The solution lets you backup and restore large data sets in a fraction of the time required for public cloud storage, leading to enhanced Recovery Point Objectives (RPO) and Recovery Time Objectives (RTO).
Security and Ransomware Protection
Cloudian is a hardened object storage system that includes enhanced security features such as secure shell, encryption, integrated firewall and RBAC/IAM access controls to protect backup copies against malware. es in a shared-storage environment. In addition, to protect data from ransomware attacks, Cloudian HyperStore and Kasten support Object Lock for air-tight data immutability all the way up to the operating system root level.
Kasten-Validated Solution
Cloudian is Kasten-validated to ensure trouble-free integration. Kasten’s native support for the S3 API enables seamless integration with Cloudian HyperStore.
Easy as 1-2-3
Setting up Kasten K10 and Cloudian Ransomware Protection is as simple as 3 easy steps:
1. Create a new target bucket on Cloudian HyperStore and enable Object Lock.
2. After Kasten K10 installation, check the “Enable Immutable Backups” box when adding a target S3 object storage bucket.
3. Validate the Cloudian object storage bucket and specify your protection period.
GET STARTED WITH KASTEN K10 TODAY!
Try the full-featured and free Edition of Kasten K10 with a fast and easy install.
Object storage is relatively new when compared with more traditional storage systems such as file or block storage. So, what is object storage, exactly? In short, it is storage for unstructured data that eliminates the scaling limitations of traditional file storage. Limitless scale is the reason that object storage is the storage of the cloud. All of the major public cloud services, including Amazon, Google and Microsoft, employ object storage as their primary storage.
This is part of an extensive series of guides about data security.
Object storage is a technology that manages data as objects. All data is stored in one large repository which may be distributed across multiple physical storage devices, instead of being divided into files or folders.
It is easier to understand object-based storage when you compare it to more traditional forms of storage – file and block storage.
File storage
File storage stores data in folders. This method, also known as hierarchical storage, simulates how paper documents are stored. When data needs to be accessed, a computer system must look for it using its path in the folder structure.
File storage uses TCP/IP as its transport, and devices typically use the NFS protocol in Linux and SMB in Windows.
Block storage
Block storage splits a file into separate data blocks, and stores each of these blocks as a separate data unit. Each block has an address, and so the storage system can find data without needing a path to a folder. This also allows data to be split into smaller pieces and stored in a distributed manner. Whenever a file is accessed, the storage system software assembles the file from the required blocks.
Block storage uses FC or iSCSI for transport, and devices operate as direct attached storage or via a storage area network (SAN).
Object storage
In object storage systems, data blocks that make up a file or “object”, together with its metadata, are all kept together. Extra metadata is added to each object, which makes it possible to access data with no hierarchy. All objects are placed in a unified address space. In order to find an object, users provide a unique ID.
Object-based storage uses TCP/IP as its transport, and devices communicate using HTTP and REST APIs.
Metadata is an important part of object storage technology. Metadata is determined by the user, and allows flexible analysis and retrieval of the data in a storage pool, based on its function and characteristics.
The main advantage of object storage is that you can group devices into large storage pools, and distribute those pools across multiple locations. This not only allows unlimited scale, but also improves resilience and high availability of the data.
Object Storage Architecture: How Does It Work?
Object storage is fundamentally different from traditional file and block storage in the way it handles data. In an object storage system, each piece of data is stored as an object, which contains both the data itself and a unique identifier, known as an object ID. This ID allows the system to locate and retrieve the object without relying on hierarchical file structures or block mappings, enabling faster and more efficient data access.
Object storage architecture typically consists of three main components: the data storage layer, the metadata index, and the API layer. Let’s take a closer look at each of these components and how they work together to create a powerful and flexible storage solution.
Data Storage Layer
The data storage layer is where the actual data objects are stored. In an object storage system, data is typically distributed across multiple storage nodes to ensure high performance, durability, and redundancy. Each storage node typically contains a combination of hard disk drives (HDDs) and solid-state drives (SSDs) to provide the optimal balance between capacity, performance, and cost. Data objects are automatically replicated across multiple nodes, ensuring that data remains available and protected even in the event of hardware failures or other disruptions.
Metadata Index
The metadata index is a critical component of object storage architecture, as it maintains a record of each object’s unique identifier, along with other relevant metadata, such as access controls, creation date, and size. This information is stored separately from the actual data, allowing the system to quickly and efficiently locate and retrieve objects based on their metadata attributes. The metadata index is designed to be highly scalable, enabling it to support millions or even billions of objects within a single object storage system.
API Layer
The API layer is responsible for providing access to the object storage system, allowing users and applications to store, retrieve, and manage data objects. Most object storage systems support a variety of standardized APIs, such as the Simple Storage Service (S3) API from Amazon Web Services (AWS), the OpenStack Swift API, and the Cloud Data Management Interface (CDMI). These APIs enable developers to easily integrate object storage into their applications, regardless of the underlying storage technology or vendor.
Object Storage Benefits
Exabyte Scalable
Unlike file or block storage, object storage services enable scalability that goes beyond exabytes. While file storage can hold many millions of files, you will eventually hit a ceiling. With unstructured data growing at 50+% per year, more and more users are hitting those limits, or they expect to in the future.
Scale Out Architecture
Object storage makes it easy to start small and grow. In enterprise storage, a simple scaling model is golden. And scale-out storage is about as simple as it gets: you simply add another node to the cluster and that capacity gets folded into the available pool.
HyperStore is an S3-compatible storage system. HyperFile is a connector that allows files to be stored on HyperStore.
Customizable Metadata
While file systems have metadata, the information is limited and basic (date/time created, date/time updated, owner, etc.). Object storage allows users to customize and add as many metadata tags as they need to easily locate the object later. For example, an X-ray could have information about the patient’s age and height, the type of injury, etc.
High Sequential Throughput Performance
Early object storage systems did not prioritize performance, but that’s now changed. Now, object stores can provide high sequential throughput performance, which makes them great for streaming large files. Also, object storage services help eliminate networking limitations. Files can be streamed in parallel over multiple pipes, boosting usable bandwidth.
Flexible Data Protection Options
To safeguard against data loss, most traditional storage options utilize fixed RAID groups (groups of hard drives joined together), sometimes in combination with data replication. The problem is, these solutions generally lead to one-size-fits-all data protection. You can not vary the protection level to suit different data types.
Object storage solutions employ a flexible tool called erasure coding that is similar to old-fashioned RAID in some ways, but is far more flexible. Data is striped across multiple drives or nodes as needed to achieve the needed protection for that data type. Between erasure coding and configurable replication, data protection is both more robust and more efficient.
Support for the S3 API
Back when object storage solutions were launched, the interfaces were proprietary. Few application developers wrote to these interfaces. Then Amazon created the Simple Storage Service, or “S3”. They also created a new interface, called the “S3 API”. The S3 API interface has since become a de-facto standard for object storage data transfer.
The existence of a de facto standard changed the game. Now, S3-compatible application developers have a stable and growing market for their applications. And service providers and S3-compatible storage vendors such as Cloudian have a growing user set deploying those applications. The combination sets the stage for rapid market growth.
Lower Total Cost of Ownership (TCO)
Cost is always a factor in storage. And object storage services offer the most compelling story, both in hardware/software costs and in management expenses. By allowing you to start small and scale, this technology minimizes waste, both in the form of extra headcount and unused space. Additionally object storage systems are inherently easy to manage. With limitless capacity within a single namespace, configurable data protection, geo replication, and policy-based tiering to the cloud, it’s a powerful tool for large-scale data management.
To learn more about Cloudian’s fully native S3-compatible storage in your data center, and how it can cut down your TCO, check out our free trial. Or visit cloudian.com for more information.
Object Storage Use Cases
There are numerous use cases for object storage, thanks to its scalability, flexibility, and ease of use. Some of the most common use cases include:
Backup and archiving
Object storage is an excellent choice for storing backup and archive data, thanks to its durability, scalability, and cost-effectiveness. The ability to store custom metadata with each object allows organizations to easily manage retention policies and ensure compliance with relevant regulations.
Big data analytics
The horizontal scalability and programmability of object storage make it a natural choice for storing and processing large volumes of unstructured data in big data analytics platforms. Custom metadata schemes can be used to enrich the data and enable more advanced analytics capabilities.
Media storage and delivery
Object storage is a popular choice for storing and delivering media files, such as images, video, and audio. Its scalability and performance make it well-suited to handling large volumes of media files, while its support for various data formats and access methods enables seamless integration with content delivery networks and other media delivery solutions.
Internet of Things (IoT)
As the number of connected IoT devices continues to grow, so too does the amount of data they generate. Object storage is well-suited to handle the storage and management of this data, thanks to its scalability, flexibility, and support for unstructured data formats.
How to Choose an Object-Based Storage Solution
When choosing an object storage solution, there are several factors to consider. Some of the most important factors include:
Scalability: One of the primary strengths of object storage is its ability to scale horizontally, so it’s essential to choose a platform that can grow with your organization’s data needs. Look for a solution that can easily accommodate massive amounts of data without sacrificing performance or manageability.
Data durability and protection: Ensuring the integrity and availability of your data is critical, so look for an object storage platform that offers robust data protection features, such as erasure coding, replication, or versioning. Additionally, consider the platform’s durability guarantees – how likely is it that your data will be lost or corrupted?
Cost: Cost is always a consideration when choosing a storage solution, and object storage is no exception. Be sure to evaluate the total cost of ownership (TCO) of the platform, including factors such as hardware, software, maintenance, and support costs. Additionally, if you’re considering a cloud-based solution, be sure to factor in the costs of data transfer and storage.
Performance: While object storage is not typically designed for high-performance, low-latency workloads, it’s still important to choose a platform that can deliver acceptable performance for your organization’s specific use cases. Consider factors such as throughput, latency, and data transfer speed when evaluating performance.
Integration and compatibility: The ability to integrate the object storage platform with your existing infrastructure and applications is essential. Look for a solution that supports industry-standard APIs and protocols, as well as compatibility with your organization’s preferred development languages and tools.
See Additional Guides on Key Data Security Topics
Together with our content partners, we have authored in-depth guides on several other topics that can also be useful as you explore the world of data security.
This website uses cookies so that we can provide you with the best user experience possible. Cookie information is stored in your browser and performs functions such as recognising you when you return to our website and helping our team to understand which sections of the website you find most interesting and useful.
Strictly Necessary Cookies
Strictly Necessary Cookie should be enabled at all times so that we can save your preferences for cookie settings.
If you disable this cookie, we will not be able to save your preferences. This means that every time you visit this website you will need to enable or disable cookies again.



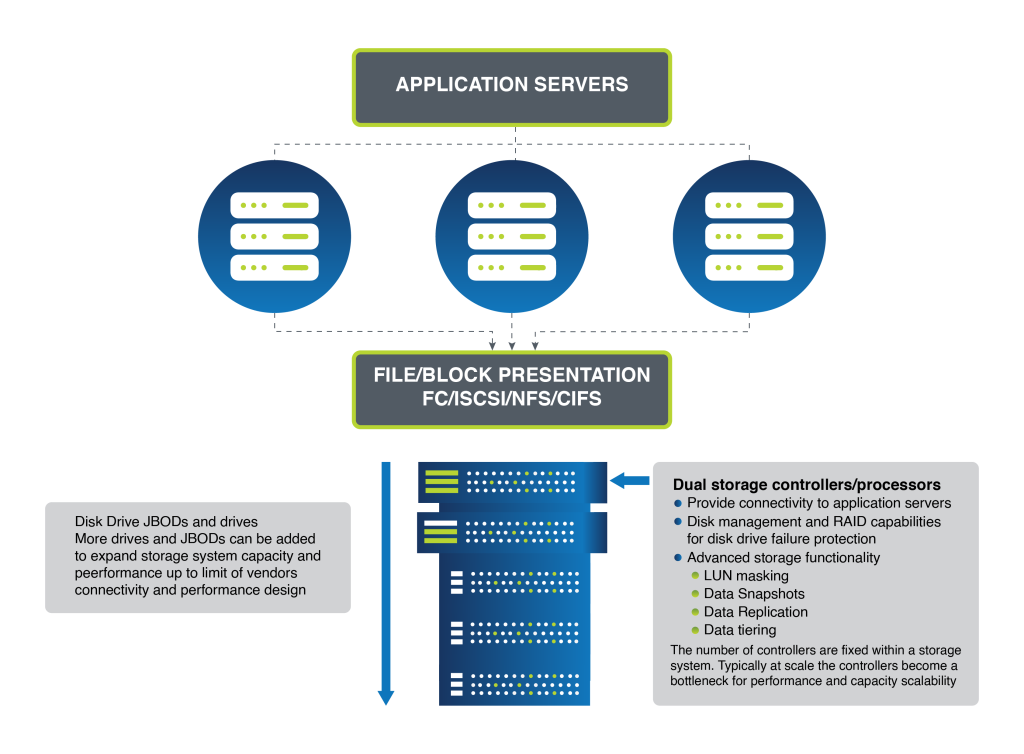
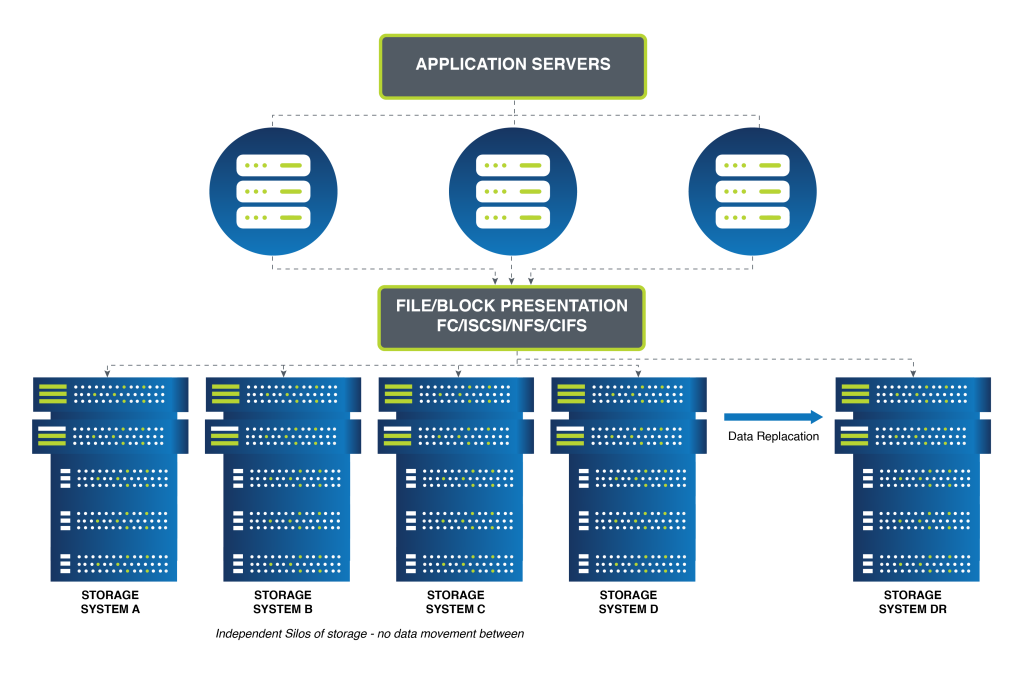
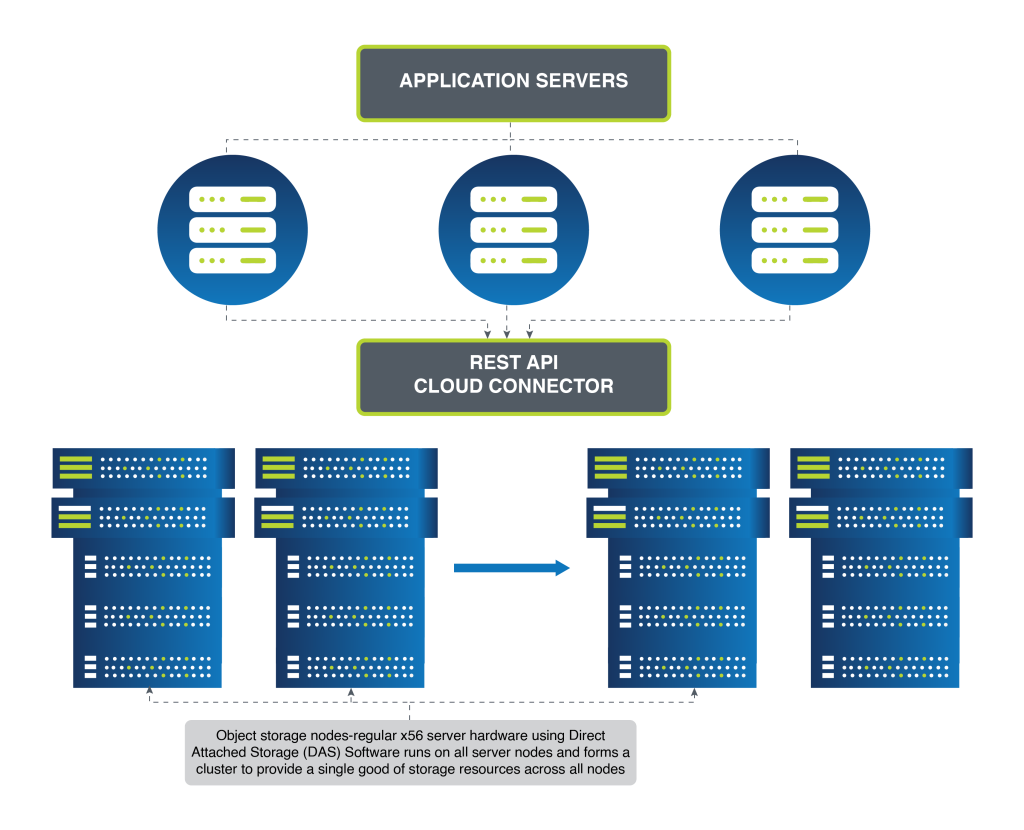


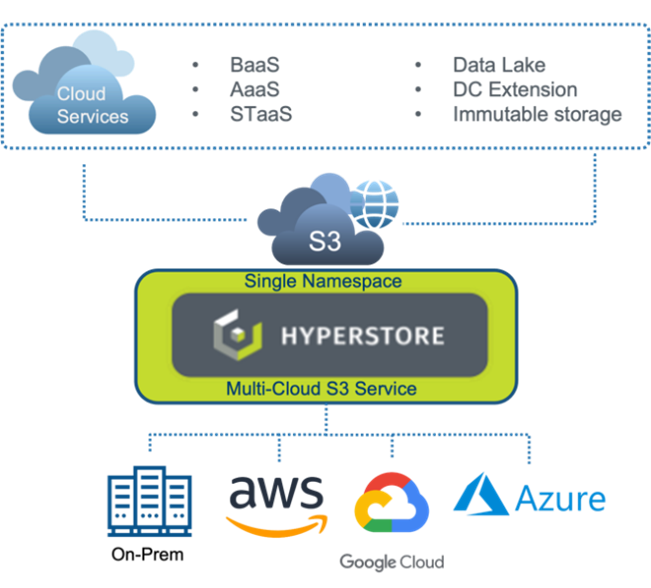
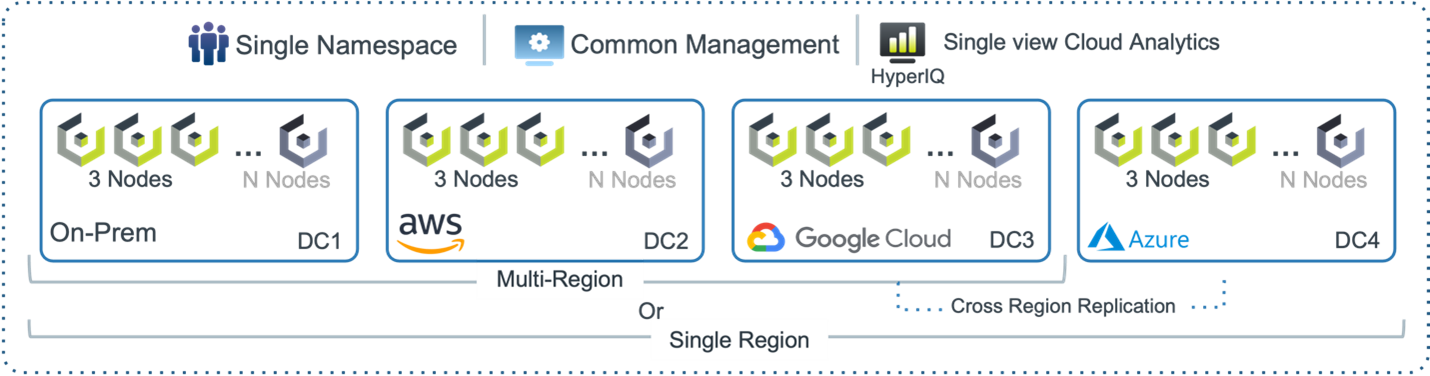
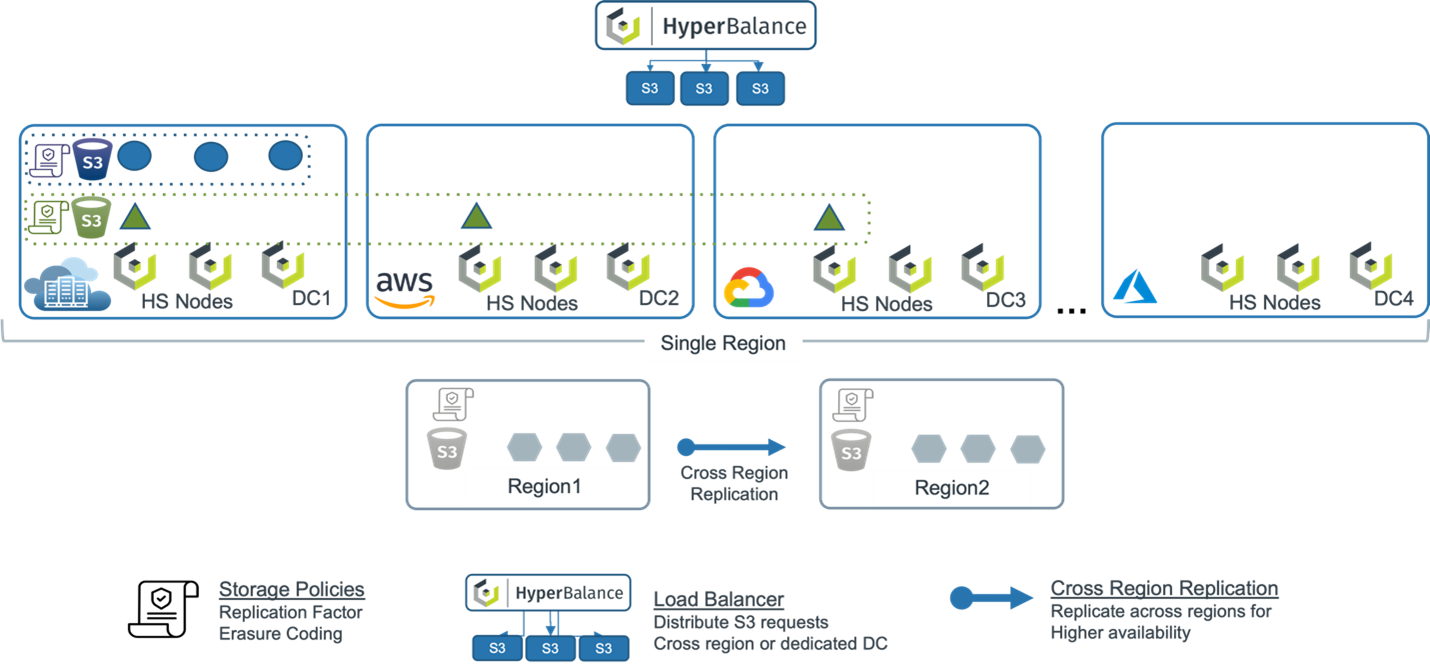


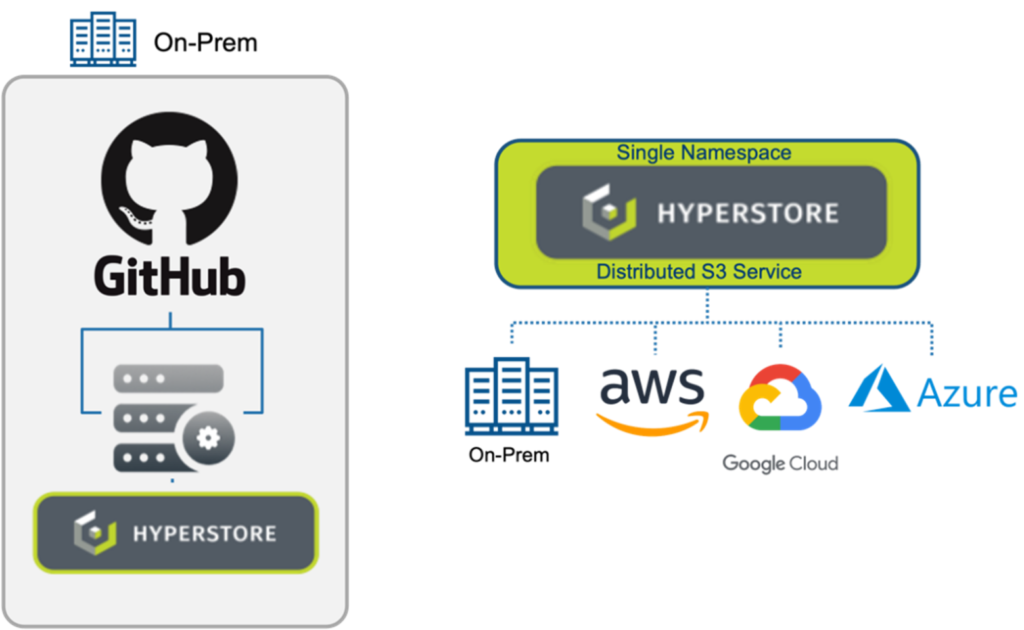
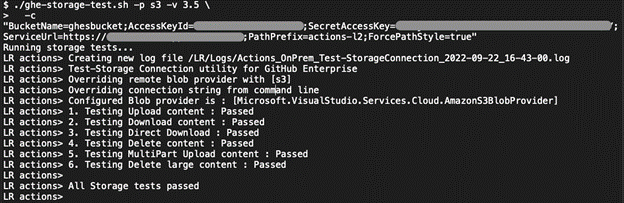
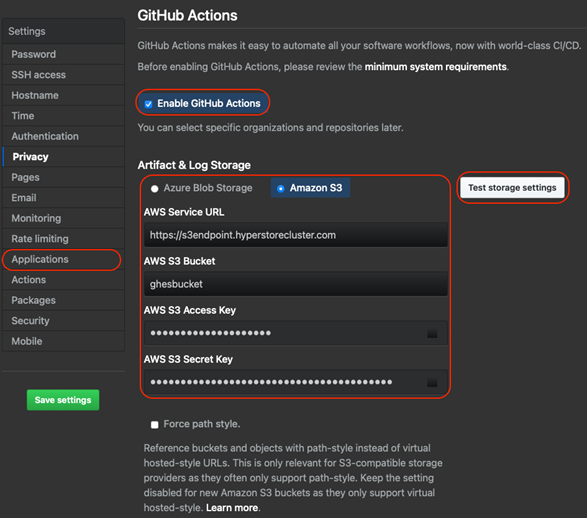
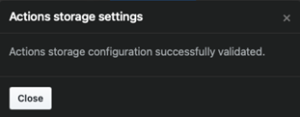
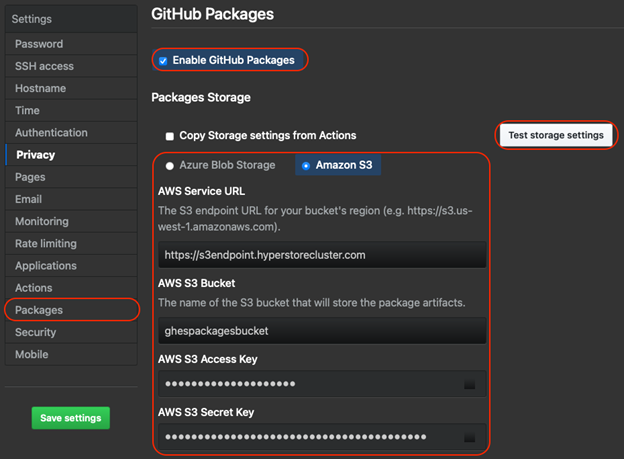

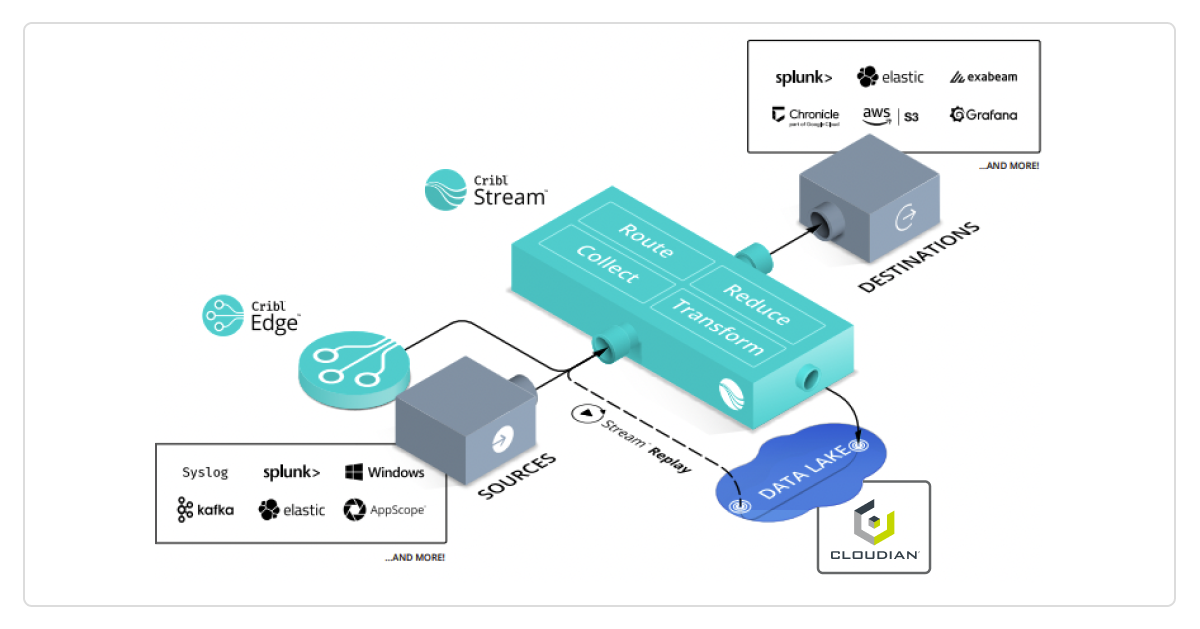

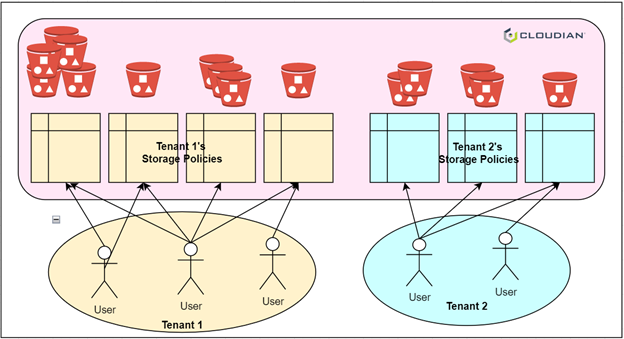
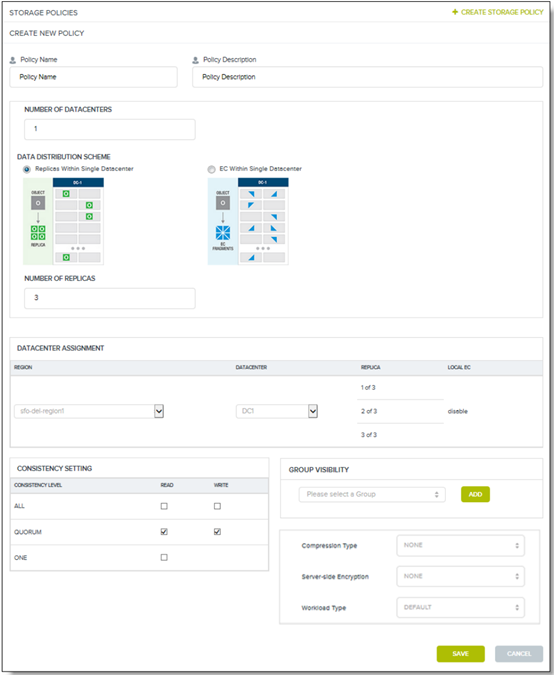
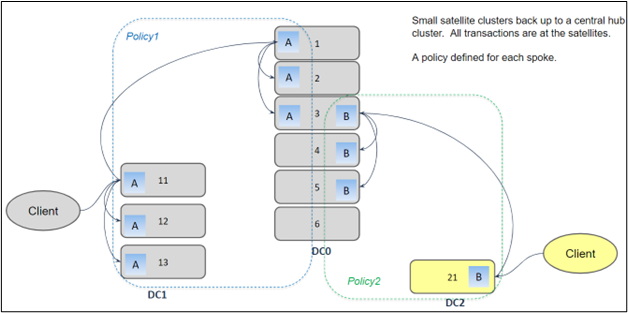
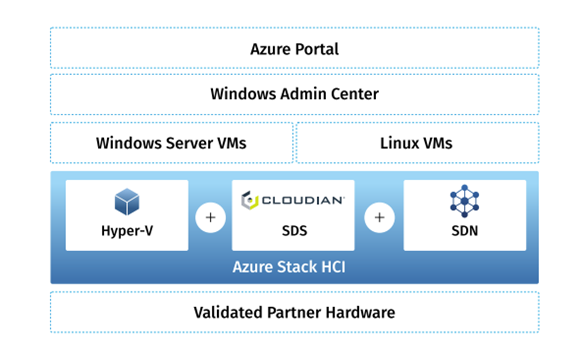 HyperStore employs policy-based tools to replicate or tier data to Azure for offsite disaster recovery, capacity expansion or data analysis in the cloud. HyperStore offers limitless scalability, multi-tenancy and military-grade security. This includes the ability to isolate storage pools using local and remote authentication methods such as Password, AD, LDAP, IAM and certificate-based authentication.
HyperStore employs policy-based tools to replicate or tier data to Azure for offsite disaster recovery, capacity expansion or data analysis in the cloud. HyperStore offers limitless scalability, multi-tenancy and military-grade security. This includes the ability to isolate storage pools using local and remote authentication methods such as Password, AD, LDAP, IAM and certificate-based authentication.

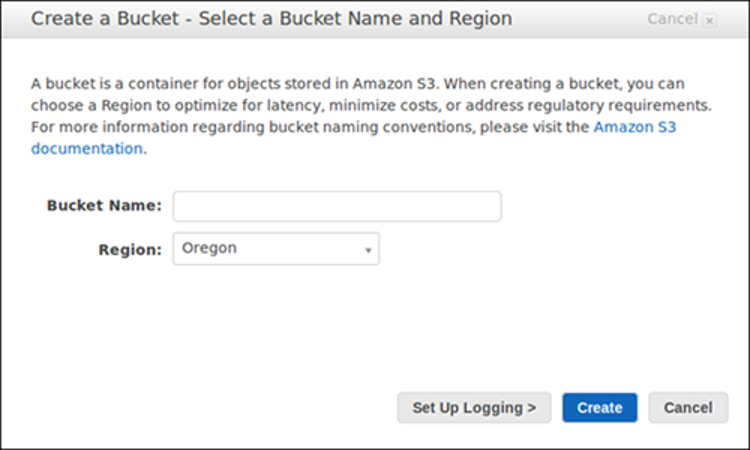

 Adam Bergh
Adam Bergh
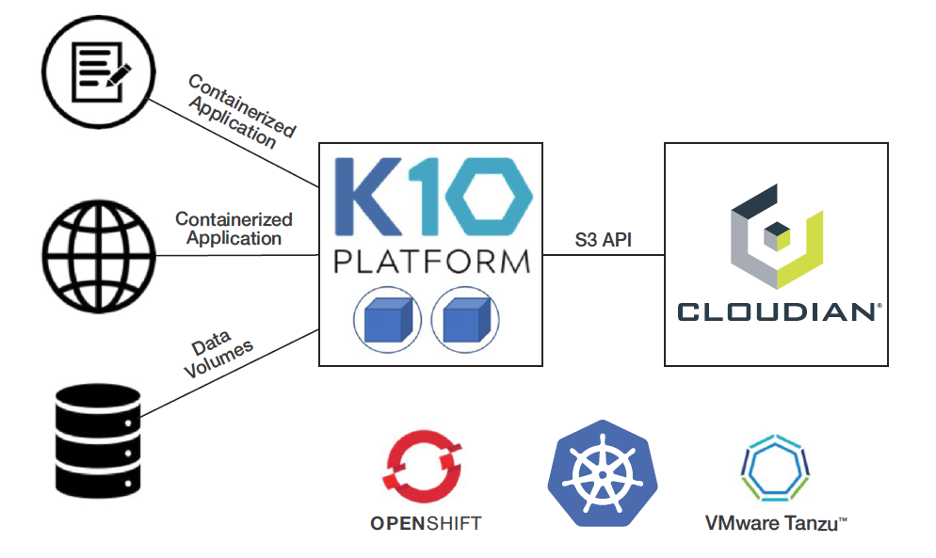
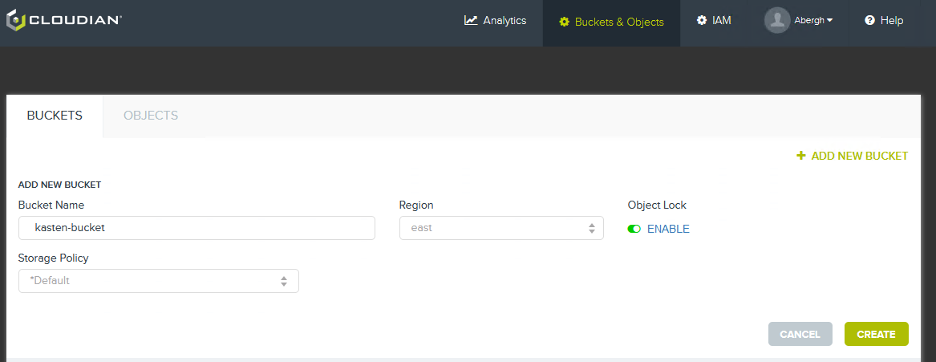
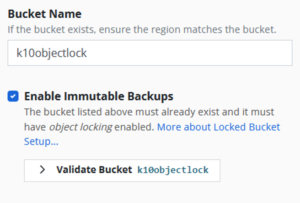
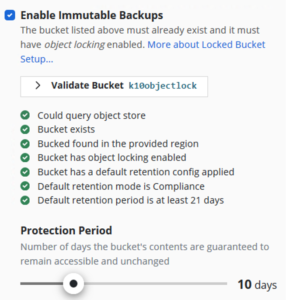
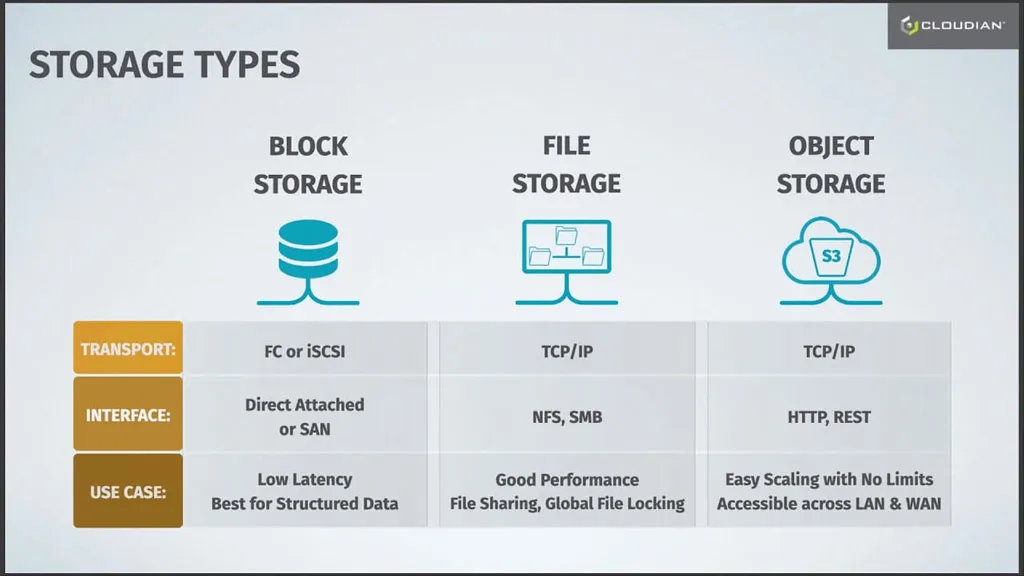



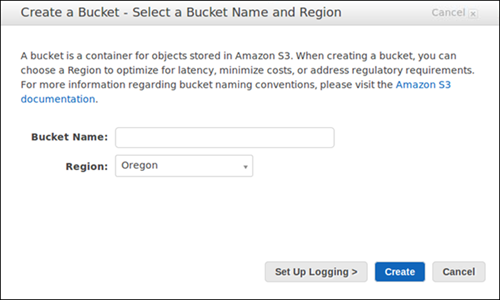{kind=link}